KNIME ANALYTICS
Guided Analytics using KNIME Analytics Platform
What is Guided Analytics?
Although the word “Guided Analytics” bring your mind to a complex state, it simply means automating data science. Guided Analytics allow a person having less expertise on data science to go through the process and see new insights hidden in their existing data. For example an IT administrator of a school can follow this process and predict future outcomes like how well th
What is KNIME?
KNIME Analytics platform is one of the most popular open source platforms used in data science to automate the data science process. KNIME has thousands of nodes in the node repository which allows you to drag and drop the nodes into the KNIME workbench. A collection of interrelated nodes creates a workflow which can be executed locally as well as can be executed it in the KNIME web portal after deploying the workflow into the KNIME server. KNIME helps to create the Guided Analytics process as a workflow in KNIME platform by helping to automate the process.
Data Science Lifecycle

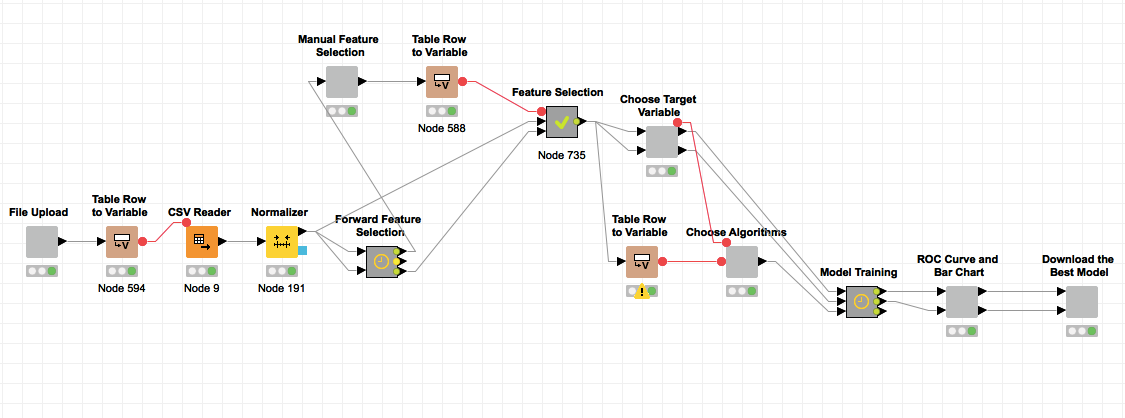
The above figure depicts the recursive data science life cycle from data cleansing to model evaluation. While introducing Guided Analytics to Virtuoso Platform of Cinglevue, we basically focused on giving a flexibility and user friendliness to Virtuoso end user. The scope of the Guided Analytics process that we have developed ranges from feature selection to model evaluation having the assumption that the user has cleaned data. The top most figure illustrates the KNIME Guided Analytics workflow that is used to achieve the aforementioned process from feature selection to model evaluation. When you deploy this workflow in KNIME server you can access it through the web portal and get user friendly wizards. Basically it allows a user to upload a dataset as a csv file as shown below.

Then the features are listed as a table with accuracy values which obtained using forward feature selection method. Basically what forward feature selection does is it iteratively adds 1 feature at a time to the model and find the accuracy score of the model after adding the particular feature. User can go through the list and select a number of features that he would think will work in the model by considering the accuracy.

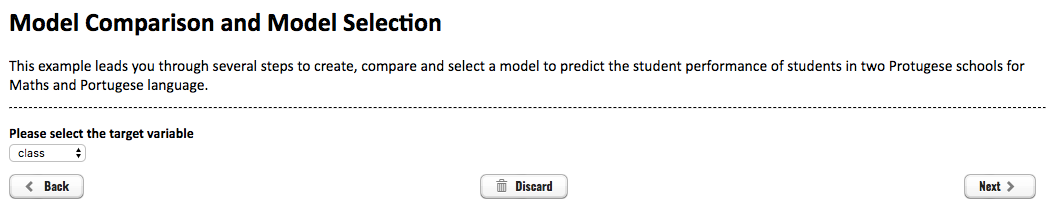
The next screen asks the user to select the target variable as depicted in below figure.
Forth screen suggests a list of classification algorithms that the user can leverage to train the dataset.

In the next screen user can have a look on which algorithm performs the best out of selected algorithms through a ROC curve and a bar chart for more understandability. The couple of figures shown below depicts that scenario.


The last step allows the user to download the best model in PMML format which allows to use in any enterprise application.

Architecture

The high level architecture of the adopted Guided Analytics process is depicted in the above figure. Analytics service is wrapped around the KNIME server which allows to list out and execute the deployed KNIME workflows. Virtuoso platform directly talk to the analytics service and execute workflows relevant to feature selection and modeling. Prediction service is implemented on top of openscoring engine. Virtuoso platform directly talks to the predict service and leverages the model deployment and model evaluation functionalities of openscoring.
How Cinglevue introduced Guided Analytics in Virtuoso Platform ?
In order to introduce Guided Analytics to Virtuoso Platform we had to breakdown the KNIME workflow depicted in top most figure into feature selection and model training for both classification and regression type of problems.

The data source access is itself done in the frontend. Significance is any dataset in csv format can be exploited to see new insights using this workflow. Soon after uploading the dataset the user needs to select the target variable. Upon the selection of target variable the rest of the extracted features are listed under Available Features list box and the user can select whatever feature he think will effect in the outcome. The selected features are sent to the KNIME server through analytics service to run a workflow and send back the evaluation metrics(accuracy) obtained. The accuracy values are obtained using forward feature selection method by adding features iteratively. The obtained accuracy values are displayed as shown in the below figure under Selected Features.

We have used accuracy as the forward feature selection criteria for classification type problems while R² as the forward feature selection criteria for regression type problems. As mentioned earlier the main guided analytics workflow has been broken down into several sub workflows and feature selection is one sub workflow. The workflow we have used in the backend is shown in the below figure.

For classification type problems we used Naive Bayes algorithm inside Forward Feature Selection meta node to predict accuracy values for the added features as shown in the below figure.

For regression type problems we used Linear Regression algorithm inside Forward Feature Selection meta node to predict R² values for the added features as shown in the below figure.

Then the next step is to select the machine learning algorithms listed according to the mining function selected under Machine Learning Method selection. If classification method is selected classification algorithms are listed and if regression method is selected regression algorithms are listed under Algorithm Selection. The selected algorithms along with the dataset and selected features are send to the KNIME server to respond back with the accuracy or R² values for the performance of selected algorithms along with the best model in PMML format. The result is shown as a bar graph as shown in the below figure.


The backend KNIME workflows for both model training in classification and regression type problems are illustrated in the below figure. The ML algorithms used inside the Model Training meta node changes according to the nature of mining function(classification or regression).

At this stage we have finished both the steps feature selection and model training. Then it comes model deployment and model evaluation. Virtuoso Platform leverages the functionalities of Openscoring engine for these two purposes.
The PMML file of the best model we obtained is deployed into the Openscoring engine using a user given model id. The deployed models are listed as depicted in the below figure.

Once the user clicks on the Evaluate button of a particular model the input fields relevant to that model are listed along with valid boundaries as shown below in the couple of figures.


Next step is evaluating the model for unseen data using this interface as shown in the below couple of figures.


The next step would be to validate the result obtained and feed the new data into retraining the models for better predictions. Will come back with another interesting blog post on retraining the models by continuing the data science lifecycle.

Comments
Post a Comment